Q. What if your Dad loses his car keys ?
A. 'Parent keys not found !'
Q. What if your old girl friend spots you with your new one ?
A. 'Duplicate value on index !'
Q. What if the golf ball doesn't get into the hole at all ?
A. 'Value larger than specified precision !'
Q. What if you try to have fun with somebody else's girlfriend and get kicked out ?
A. 'Insufficient privileges on the specified object!'
Q. What if you don't get any response from the girl next door ?
A. 'No data found !' or 'Query caused no rows retrieved !'
Q. What if you get response from the girl next door and her Mom too ?
A. 'SELECT INTO returns too many rows !'
Q. What if you dial a wrong number ?
A. 'Invalid number' or ' Object doesn't exist !'
Q. What if you try to beat your own trumpet ?
A. 'Object is found mutating !'
Q. What if you are too late to office and the boss catches you ?
A. 'Discrete transaction failed !'
Q. What if you see 'theatre full' when you go to a movie ?
A. 'Maximum number of users exceeded !'
Q. What if you don't get table in the lunch room ?
A. 'System out of space !'
Tuesday, July 28, 2009
Database Answers To Real Life Questions -- Creative Joke
Parameter Sniffing & Stored Procedures Execution Plan
"Parameter sniffing" refers to a process whereby SQL Server's execution environment "sniffs" the current parameter values during compilation or recompilation, and passes it along to the query optimizer so that they can be used to generate potentially faster query execution plans. The word "current" refers to the parameter values present in the statement call that caused a compilation or a recompilation.
Check out the complete article about Parameter sniffing
Thursday, July 23, 2009
Columnar Database - New Tech in BI space
I came accross very interesting database design to hold huge amounts of data. It's not a traditional RDBMS system. It's totally different.
A column-oriented DBMS is a database management system (DBMS) which stores its content by column rather than by row. This has advantages for databases such as data warehouses and library catalogues, where aggregates are computed over large numbers of similar data items. This approach is contrasted with row-oriented databases and with correlation databases, which use a value-based storage structure.
Check out the basics of Columnar database
Few points about this database from MVP and SQLServerBible Author, Paul Nielsen
Friday, July 17, 2009
Why We should Use EXISTS instead of DISTINCT to improve Query Performance
Today, I am going to give you a tip to improve the query performance when you are using DISTINCT to eliminate duplicate records.
My team member wants to find all the department names where each department has at least one employee.
So his query is:
SELECT distinct D.DEPARTMENT_ID,D.DEPARTMENT_NAME
FROM DEPARTMENT D INNER JOIN EMPLOYEE E
ON D.DEPARTMENT_ID = E.DEPARTMENT_ID
This is Ok where my team member is joining Employee and Department table and then taking distinct department Names and IDs.
Lets look at the execution plan: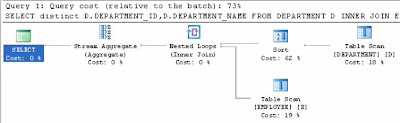
Estimated Sub Tree Cost : 0.0182019
Query Cost : 73%
My Query is:
When I look at the requirement little bit close, the requrement says If the department has atleast one employee then return the department Name. The perfect solution which satisfies this requirement is with EXISTS.
So I modified the query with the EXISTS clause.
SELECT D.DEPARTMENT_ID,D.DEPARTMENT_NAME
FROM DEPARTMENT D WHERE EXISTS (SELECT 1 FROM EMPLOYEE E WHERE D.DEPARTMENT_ID = E.DEPARTMENT_ID)
Lets look at the execution plan:
Estimated Sub Tree Cost : 0.0067844
Query Cost : 27%
As you can see from the results there is signifact of difference in the Query Cost.
So use EXISTS instead of DISTINCT. Also it doesn't mean that it EXISTS can be used at all the places where you have DISTINCT. This basically on case by case.
Thursday, July 16, 2009
Processing Order of SELECT Statement
In my previous article I talked about what happens when you issue INSERT statement. In this article I am going to talk about Processing order of a SELECT statement.
1. FROM
2. ON
3. JOIN
4. WHERE
5. GROUP BY
6. HAVING
7. SELECT
8. DISTINCT
9. ORDER BY
10. TOP
Tuesday, July 14, 2009
Enable SQL Full-text Filter daemon Launcher Process
In this post I would like to give you simple tip to enable SQL Full-text Filter daemon Launcher (MSSQLSERVER):
This navigation is based on XP:
1) Click Start Menu
2) Go to All Programs
3) Go to Microsoft SQL Server 2008
4) Go to Configuration Tools
5) Click on SQL Server Configuration Manager
6) Click on SQL Server Services in the Left Pane.
7) On the Right hand side you should see a row with the name SQL Full-text Filter Daemon Launcher (MSSQLSERVER).
8) Right Click on this and go to Properties
9) Go to Service tab
10) Change the start mode to Automatic.
11) Go to Logon and Click Start button to start.
That’s it.
How to find whether Full Text is Installed or not?
In this post I would like to give you simple tip to find out whether Full Text is installed or not.
Just run the below query in SQL Server Management Studio.
SELECT FULLTEXTSERVICEPROPERTY('IsFulltextInstalled')
Or
SELECT SERVERPROPERTY('IsFullTextInstalled')
If the above query returns value 1, that means Full text is installed.
Why we should avoid * in SELECT Clause to improve query performance
Why SQL Server experts say don’t use * in SELECT clause. Always use the columns what you need. In this article I am going to list out the points with examples on why we should avoid * in the SELECT clause.
Let’s create a table with 100K records. In my case I created VJ_TEST table based sys.sysmessages using SELECT statement. To test the performance of the query you really need a big table.
Step 1: Creating a test table
select * into VJ_TEST from sys.sysmessages
From this table, I need Error,Description columns to my application based on Severity column. i.e. When ever I query this table I always use severity column.
So I created a Covering index on these columns.
Step 2: Creating Covering Index
CREATE NONCLUSTERED INDEX IDX_VJ_TEST ON VJ_TEST(SEVERITY) INCLUDE (Error,description)
Step 3A: Query the table using * and see the execution plan.
SELECT * from VJ_TEST WHERE SEVERITY = 24
Estimated CPU Cost is 0.0004598
Estimated SubTree Cost is 0.356421
Though this query is using Index to filter the records but it is still scaning the table to get all the columns.
Step 3B: Query the table using Columns and see the execution plan.
SELECT Error,description from VJ_TEST WHERE SEVERITY = 24

Estimated CPU Cost is 0.000278
Estimated SubTree Cost is 0.0048638
As you can see by specifying the columns in the where clause it is going for Index Seek.
So based on this excersise we can say using columns in where clause always faster than using *.
Point 1: Always use the required Columns in the SELECT clause
Point 2: If you are transfering less data over the network then it will ocupy less bandwidth and faster to send.
Point 3: From look and feel point of view it would be very good and easy to understand.
Monday, July 13, 2009
Could not open a connection to SQL Server
Today, I was trying to connect to SQL Server and I got the below message. I don’t know what went wrong I restarted my machine.
Error:
A network-related or instance-specific error occurred while establishing a connection to SQL Server. The server was not found or was not accessible. Verify that the instance name is correct and that SQL Server is configured to allow remote connections. (provider: Shared Memory Provider, error: 40 - Could not open a connection to SQL Server) (Microsoft SQL Server, Error: 2)
Solution:
I did little bit of R&D around this. What I am trying to do is using SSMS connecting to the SQL Server. SSMS is a front-end tool for SQL operations. And the error message shows that "Could not open a connection to SQL Server".
So I thought SQL Server service is not running. So I opened SQL Server Configuration wizard to see if I am right or wrong. Yes I am right. SQL Server service is stopped. I restarted the service and now everything looks fine.
Thursday, July 9, 2009
What to do when SELECT query is Running Slowly?
In this post, i would like to give you 10 simple tips to follow when query is running slowly.
1) Review objects involved in the Query.
-- 1.1) Make sure you dont have any other columns in the SELECT clause which are not used any where in the application or in any other code.
-- 1.2) Make sure you are not using * to retrieve the columns from the table when you are not interested in all the columns.
2) Close look at the tables and their structures.
-- 2.1) Gather the No.Of Records in the table and Access pattern of the table.
-- 2.2) Make sure the table is partitioned if it holds huge amount of data.
-- 2.3) Gather the Indexes information on these tables.
-- 2.4) Make sure you are using Alias to the tables, if you have too many tables in FROM clause.
3) Very Close look at the Joining conditions in WHERE clause.
-- 3.1) Verify the joining conditions between the tables.
-- 3.2) For N tables in FROM clause you should have atleast N-1 where conditions.
-- 3.3) Make sure your query is not producing cartesian product.
4) Check on the Joining columns for data type conversions.
-- 4.1) Make sure you are not comparing Numbes with Char. etc. If you are doing this then there is an issue in the Table design. If you can't alter the column the try to denormalize the table. which means have duplicate information. If this takes less time to implement.
5) Check on the Joining columns for any functions
-- 5.1) Make sure you are not using any functions on the Joining columns. Its important to note that if you use any functions on the indexed columns in WHERE clause then engine will not use the Index to fetch or locate the data.
6) Check these Joining columns against Indexes on the table and Order of the columns in the Index.
-- 6.1) Make sure the order of the columns in WHERE clause should match with the Order of the columns in the Index.
7) Look at the Actual Execution Plan and see if there is anything strange.
-- 7.1) Look at the execution plan and take necessary actions like adding hint or creating a covering Index or Indexed views or make use of the temp table to break the logic of the query critieria.
8) Check whether statistics are up to date.
-- 8.1) This is very important step. If the stats are not up to date then this can lead the engine to take wrong path to locate the data and taking wrong path means that full scan is made when an index scan would have been appropriate.
9) Run the trace to find more information around the query.
-- 9.1) SQL Server Profiler shows how SQL Server resolves queries internally. SQL:BatchCompleted event and the RPC:CompletedEvent events should capture performance for all your SQL batches and stored procedures. The main attributes in trace are Reads, Writes, Duration, CPU, EndTime.
10) Run the Query using Database Engine Tuning Advisor.
-- 10.1) Database Engine Tuning Advisor is used examine how queries are processed in the databases and then it recommends how you can improve query performance by providing tips on having additional indexes.
This article is mainly to give general tips and these are very common tips. There are no hard and fast rules to solve Query performance issues. Its completly based on the queries and the requirement and most importantly, it is specific to the environment.
Hopefully i can come up with an article with all the measures.
Wednesday, July 8, 2009
Find out the objects on which the view depends either directly or indirectly
I would like to give you a simple query to find out objects where view depends on either directly or in-directly.
so Lets create few tables and views to test the query.
-- To Create EMPLOYEE Table
CREATE TABLE [dbo].[EMPLOYEE](
[EMP_ID] [int] IDENTITY(1,1) NOT NULL,
[FIRST_NAME] [varchar](30) NULL,
[MIDLE_NAME] [varchar](30) NULL,
[LAST_NAME] [varchar](30) NULL,
[SALARY] [bigint] NULL,
[DEPARTMENT_ID] [int] NULL
)
-- To Create DEPARTMENT table
CREATE TABLE [dbo].[DEPARTMENT](
[DEPARTMENT_ID] [int] IDENTITY(10,10) NOT NULL,
[DEPARTMENT_NAME] [varchar](30) NULL
)
-- Test View 1
CREATE VIEW V_Emp_Info as
SELECT E.*,( SELECT D.DEPARTMENT_NAME FROM DEPARTMENT D WHERE D.DEPARTMENT_ID = E.DEPARTMENT_ID ) AS DEPT_NAME
FROM EMPLOYEE E
-- Test View 2
CREATE VIEW V_EMP_TEST AS
SELECT V.* FROM EMPLOYEE E, V_EMP_INFO V
WHERE E.FIRST_NAME = V.FIRST_NAME
-- Query to get all the objects on this this view depends either directly or indirectly.
WITH Depends_CTE AS (
SELECT VIEW_SCHEMA,TABLE_CATALOG,TABLE_SCHEMA,TABLE_NAME ,VIEW_NAME, CAST('Directly' AS VARCHAR(30)) as How
FROM Information_Schema.View_Table_Usage
WHERE VIEW_NAME = 'V_EMP_TEST'
UNION ALL
SELECT e.VIEW_SCHEMA,e.TABLE_CATALOG,e.TABLE_SCHEMA,e.TABLE_NAME ,e.VIEW_NAME,CAST('In-Directly' AS VARCHAR(30)) AS HOW
FROM Information_Schema.View_Table_Usage e
INNER JOIN Depends_CTE d ON e.VIEW_NAME = d.TABLE_NAME
)
SELECT *
FROM Depends_CTE
Just pass the view name to the query.
This implementation is using Recursive CTEs (Common Table Expressions).
Tuesday, July 7, 2009
Generate DDL of a Table Using SQL Server Management Studio
>>>> Open and Login into SQL Server Management Studio (SSMS)
>>>> Choose the database in the Object Explorer
>>>> Expand the Tables section
>>>> Right Click on the Table Name and Script Table As > CREATE to > New Query Editor Window. (Please look at the below picture).
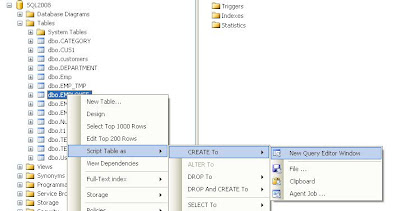
This will open a new window with CREATE Table statement.
Date Format using CONVERT function in SQL Server
Today, i would like to list out various styles of date display formats. These are very helpful for the Front-end application programmers where they want to display different date formats.
Various date style formats can be produced with CONVERT function. CONVERT function need 3 parameters.
CONVERT ( data_type [ ( length ) ] , expression [ , style ] )
The first parameter is return data type, second parameter is expression, third parameter which is optional parameter defines the style.
NOTE: Do not apply CONVERT function on date column when it is Indexed.
with out waiting lets look at the various styles of date values.
The below query produces the output in MON DD YYYY HH:MIAMPM format.
SELECT CONVERT(VARCHAR(30),GETDATE(),100)
--Output (MON DD YYYY HH:MIAMPM)
--Jul 7 2009 2:19PM
The below query produces the output in MM/DD/YYYY format.
SELECT CONVERT(VARCHAR(30),GETDATE(),101)
--Output (MM/DD/YYYY)
--07/07/2009
The below query produces the output in YYYY.MM.DD format.
SELECT CONVERT(VARCHAR(30),GETDATE(),102)
--Output (YYYY.MM.DD)
--2009.07.07
The below query produces the output in DD/MM/YYYY format.
SELECT CONVERT(VARCHAR(30),GETDATE(),103)
--Output (DD/MM/YYYY)
--06/07/2009
The below query produces the output in DD.MM.YYYY format.
SELECT CONVERT(VARCHAR(30),GETDATE(),104)
--Output (DD.MM.YYYY)
--06.07.2009
The below query produces the output in DD-MM-YYYY format.
SELECT CONVERT(VARCHAR(30),GETDATE(),105)
--Output (DD-MM-YYYY)
--06-07-2009
The below query produces the output in DD MON YYYY format.
SELECT CONVERT(VARCHAR(30),GETDATE(),106)
--Output (DD MON YYYY)
--06 Jul 2009
The below query produces the output in MON DD,YYYY format.
SELECT CONVERT(VARCHAR(30),GETDATE(),107)
--Output (MON DD,YYYY)
--Jul 06, 2009
The below query produces the output in HH24:MI:SS format.
SELECT CONVERT(VARCHAR(30),GETDATE(),108)
--Output (HH24:MI:SS)
--14:24:20
The below query produces the output in MON DD YYYY HH:MI:SS:NNN AMPM format. Use 113 style to get date and time with nano seconds in AM/PM format.
SELECT CONVERT(VARCHAR(30),GETDATE(),109)
--Output (MON DD YYYY HH:MI:SS:NNN AMPM)
--Jul 7 2009 2:24:35:490PM
The below query produces the output in MM-DD-YYYY format.
SELECT CONVERT(VARCHAR(30),GETDATE(),110)
--Output (MM-DD-YYYY)
-- 07-07-2009
The below query produces the output in YYYY/MM/DD format.
SELECT CONVERT(VARCHAR(30),GETDATE(),111)
--Output (YYYY/MM/DD)
--2009/07/07
The below query produces the output in YYYYMMDD format.
SELECT CONVERT(VARCHAR(30),GETDATE(),112)
--Output (YYYYMMDD)
--20090707
The below query produces the output in MON DD YYYY HH24:MI:SS:NNN format. Use 113 style to get date and time with nano seconds in 24 Hour Format.
SELECT CONVERT(VARCHAR(30),GETDATE(),113)
--Output (MON DD YYYY HH24:MI:SS:NNN)
--07 Jul 2009 14:26:24:617
The below query produces the output in HH24:MI:SS:NNN format. Use 114 Style to extract Time part with nano seconds in 24 Hour Format.
SELECT CONVERT(VARCHAR(30),GETDATE(),114)
--Output (HH24:MI:SS:NNN)
--14:26:48:953
Monday, July 6, 2009
Information Schema Views in SQL Server
In this article, I would like to list out the SQL Server metadata tables which we need in our day-to-day work.
SELECT * FROM Information_Schema.CHECK_CONSTRAINTS
-- Contains one row for each CHECK constraint in the current database.
SELECT * FROM Information_Schema.COLUMN_DOMAIN_USAGE
-- Contains one row for each column, in the current database, that has a user-defined data type.
SELECT * FROM Information_Schema.COLUMN_PRIVILEGES
--Contains one row for each column with a privilege either granted to or by the current user in the current database
SELECT * FROM Information_Schema.COLUMNS
--Contains one row for each column accessible to the current user in the current database.
SELECT * FROM Information_Schema.CONSTRAINT_COLUMN_USAGE
--Contains one row for each column, in the current database, that has a constraint defined on it.
SELECT * FROM Information_Schema.CONSTRAINT_TABLE_USAGE
--Contains one row for each table, in the current database, that has a constraint defined on it.
SELECT * FROM Information_Schema.DOMAIN_CONSTRAINTS
--Contains one row for each user-defined data type, accessible to the current user in the current database, with a rule bound to it.
SELECT * FROM Information_Schema.DOMAINS
--Contains one row for each user-defined data type accessible to the current user in the current database.
SELECT * FROM Information_Schema.KEY_COLUMN_USAGE
--Contains one row for each column, in the current database, that is constrained as a key.
SELECT * FROM Information_Schema.PARAMETERS
--Contains one row for each parameter of a user-defined function or stored procedure accessible to the current user in the current database.
SELECT * FROM Information_Schema.REFERENTIAL_CONSTRAINTS
--Contains one row for each foreign constraint in the current database.
SELECT * FROM Information_Schema.ROUTINE_COLUMNS
--Contains one row for each column returned by the table-valued functions accessible to the current user in the current database.
SELECT * FROM Information_Schema.ROUTINES
--Contains one row for each stored procedure and function accessible to the current user in the current database.
SELECT * FROM Information_Schema.SCHEMATA
--Contains one row for each database that has permissions for the current user.
SELECT * FROM Information_Schema.TABLE_CONSTRAINTS
--Contains one row for each table constraint in the current database.
SELECT * FROM Information_Schema.TABLE_PRIVILEGES
--Contains one row for each table privilege granted to or by the current user in the current database.
SELECT * FROM Information_Schema.TABLES
--Contains one row for each table in the current database for which the current user has permissions.
SELECT * FROM Information_Schema.VIEW_COLUMN_USAGE
--Contains one row for each column, in the current database, used in a view definition.
SELECT * FROM Information_Schema.VIEW_TABLE_USAGE
--Contains one row for each table, in the current database, used in a view.
SELECT * FROM Information_Schema.VIEWS
--Contains one row for views accessible to the current user in the current database.
Reference :





