Today, I am going to give you a tip to improve the query performance when you are using DISTINCT to eliminate duplicate records.
My team member wants to find all the department names where each department has at least one employee.
So his query is:
SELECT distinct D.DEPARTMENT_ID,D.DEPARTMENT_NAME
FROM DEPARTMENT D INNER JOIN EMPLOYEE E
ON D.DEPARTMENT_ID = E.DEPARTMENT_ID
This is Ok where my team member is joining Employee and Department table and then taking distinct department Names and IDs.
Lets look at the execution plan: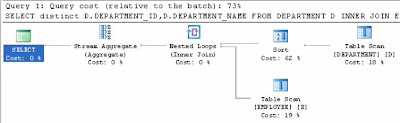
Estimated Sub Tree Cost : 0.0182019
Query Cost : 73%
My Query is:
When I look at the requirement little bit close, the requrement says If the department has atleast one employee then return the department Name. The perfect solution which satisfies this requirement is with EXISTS.
So I modified the query with the EXISTS clause.
SELECT D.DEPARTMENT_ID,D.DEPARTMENT_NAME
FROM DEPARTMENT D WHERE EXISTS (SELECT 1 FROM EMPLOYEE E WHERE D.DEPARTMENT_ID = E.DEPARTMENT_ID)
Lets look at the execution plan:
Estimated Sub Tree Cost : 0.0067844
Query Cost : 27%
As you can see from the results there is signifact of difference in the Query Cost.
So use EXISTS instead of DISTINCT. Also it doesn't mean that it EXISTS can be used at all the places where you have DISTINCT. This basically on case by case.
Friday, July 17, 2009
Why We should Use EXISTS instead of DISTINCT to improve Query Performance
Subscribe to:
Post Comments (Atom)






6 comments:
It's an interesting analysis and probably a useful conclusion; but I think your initial premise is a bit rigid. DISTINCT is not an indication of duplicate rows in a table; it's used to filter out duplicate rows in the result set, and as such is quite useful in certain contexts. My apologies if I am misunderstanding your premise.
This is crap. Your new sql is not satisfying the requirement at all! DISTINCT is to filter out result set, dude
Hi Gary,
Thanks for visit to my blog and your comment. I agree with your comment about DISTINCT. Actually i didn't set the right context when I wrote few lines about DISTINCT. These lines were completely based on the problem which i am trying to solve.
Hi Anonymous
If the SQL query result set is producing duplicate records then only we will apply DISTINCT clause. There could be many reasons behind this. Some of them are:
1) Table has duplicate records.
2) Joins are not properly placed in the WHERE clause.
3) Certain columns are not used in the Result set, becuase of which it looks like a duplicate record.
My statement says "First of all, if you have DISTINCT in the SELECT clause that means there is something wrong with the joins. So you should check the joins in where clause first and then verify the data in the base tables to eliminate any duplicate records at the table level rather than applying DISTINCT at the query level."
This is in related to case 3. where certain columns are not used in the result set to make the row unique.
I dont think i am wrong any where in this. Also when you are writing your comments, make sure you use right language. This is not your notebook, what ever you want can write.
Also, DISTINCT is used only to eliminate the records, other than this i dont see any use of this.
I would be gald if you could the SQL which satisfies my requirement.
As i am a beginer in SQL, i can learn something from you.
I think you should check your indexes before, and only then look differences.. :)
Table scan produces very poor performance.
Thank you buddy,
The information was very useful in solving my issue related to the DISTINCT clause..
Post a Comment